Schedule
目录
Text Processing Team Schedule
Members
Former Members
- Rong Liu (刘荣) : 优酷
- Xiaoxi Wang (王晓曦) : 图灵机器人
- Xi Ma (马习) : 清华大学研究生
- DongXu Zhang (张东旭) : --
- Yiqiao Pan (潘一桥):继续读研
Current Members
- Tianyi Luo (骆天一)
- Chao Xing (邢超)
- Qixin Wang (王琪鑫)
- Aodong Li (李傲冬)
- Aiting Liu (刘艾婷)
- Ziwei Bai (白子薇)
Work Process
2016-06-23
Learning Better Embeddings for Rare Words Using Distributional Representations pdf
Hierarchical Attention Networks for Document Classification pdf
Hierarchical Recurrent Neural Network for Document Modeling pdf
Learning Distributed Representations of Sentences from Unlabelled Data pdf
Speech Synthesis Based on HiddenMarkov Models pdf
Research Task
Binary Word Embedding(Aiting)
2016-06-05: find out that tensorflow does not provide logical derivation method.
2016-06-01: complete the first version of binary word embedding model
2016-05-28: complete the word2vec model in tensorflow
2016-05-25: write my own version of word2vec model
2016-05-23:
1.get tensorflow's word2vec model from(https://github.com/tensorflow/tensorflow/tree/master/tensorflow/models/embedding) 2.learn word2vec_basic model 3.run word2vec.py and word2vec_optimized.py
2016-05-22:
1.find the tf.logical_xor(x,y) method in tensorflow to compute Hamming distance.
2.learn tensorflow's word2vec model
2016-05-21:
1.read Lantian's paper 'Binary Speaker Embedding'
2.try to find a formula in tensorflow to compute Hamming distance.
Ordered Word Embedding(Aodong)
- 2016-07-12 : Complete the mixed initialization version of Rare Word Embedding and start training
- 2016-07-11 :
Improve the predict process of chatting model Changing some hyperparameters of the chatting model to speed up the training process
- 2016-07-09, 10 : Try to carry out paper's low-freq word experiment, and do some readings both from PRML and Hang Li's paper.
- 2016-07-08 : Do model selections and the model finally set off on the server.
- 2016-07-07 : Complete the chatting model and run on Huilian's server, in order to overcome the GPU memory problem.
- 2016-07-06 : Finally complete translate model in tensorflow!!!! Now I am dealing with the out of memory problem.
- 2016-07-05 :
Code predict process Although I've got a low cost value, the predict result does not compatible as expected, even the input of predict process from training set When I tried the Weibo data, program collapsed with an out of memory error.
- 2016-07-04 : Complete Coding training process
- 2016-07-01, 02: The cost function is very bumpy, debug it, while it's quite difficult!
- 2016-06-27, 28, 29 : Coding
- 2016-06-26 : Code tf's GRU and attention model
- 2016-06-25 : Read tf's source code rnn_cell.py and seq2seq.py
- 2016-06-24 :
Code spearman correlation coefficient and experiment Read Li's paper "Neural Responding Machine for Short-Text Conversation"
- 2016-06-23 :
Share paper "Learning Better Embeddings for Rare Words Using Distributional Representations" experiment and receive new task
- 2016-06-22 :
Experiment on low-frequency words Roughly read "Online Learning of Interpretable Word Embeddings" Roughly read "Learning Better Embeddings for Rare Words Using Distributional Representations"
- 2016-06-21 : Experiment and calculate cosine distance between words
- 2016-06-20 : Something went wrong with my program and fix it, so I have to start it all over again
- 2016-06-04 : Experiment the semantic&syntactic analysis of retrained word vector
- 2016-06-03 : Complete coding retrain process of low-freq word and experiment the semantic&syntactic analysis
- 2016-06-02 : Complete coding predict process of low-freq word and experiment the semantic&syntactic analysis
- 2016-06-01 : Read "Distributed Representations of Words and Phrases and their Compositionality"
- 2016-05-31 :
Read Mikolov's ppt about his word embedding papers test the randomness of word2vec and there is nothing different in single thread while rerunning the program Download dataset "microsoft syntactic test set", "wordsim353", and "simlex-999"
- 2016-05-30 : Read "Hierarchical Probabilistic Neural Network Language Model" and "word2vec Explained: Deriving Mikolov's Negative-Sampling Word-Embedding Method"
- 2016-05-27 : Reread word2vec paper and read C-version word2vec.
- 2016-05-24 : Understand word2vec in TensorFlow, and because of some uncompleted functions, I determine to adapt the source of C-versioned word2vec.
- 2016-05-23 :
Basic setup of TensorFlow Read code of word2vec in TensorFlow
- 2016-05-22 :
Learn about algorithms in word2vec Read low-freq word papar and learn about 6 strategies
Matrix Factorization(Ziwei)
2016-06-23:
prepare for report
2016-05-28:
learn the code 'matrix-factorization.py','count_word_frequence.py',and 'reduce_rawtext_matrix_factorization.py'
problem:I have no idea how to run the program and where the data.
2016-05-23:
read the code 'map_rawtext_matrix_factorization.py'
2016-05-22:
learn the rest of paper ‘Neural word Embedding as implicit matrix factorization’
2016-05-21:
learn the ‘abstract’ and ‘introduction’ of paper ‘Neural word Embedding as implicit matrix factorization’
Question answering system
Chao Xing
2016-05-30 ~ 2016-06-04 :
Deliver CDSSM model to huilan.
2016-05-29 :
Package chatting model in practice.
2016-05-28 :
Modify bugs...
2016-05-27 :
Train large scale model, find some problem.
2016-05-26 :
Modify test program for large scale testing process.
2016-05-24 :
Build CDSSM model in huilan's machine.
2016-05-23 :
Find three things to do.
1. Cost function change to maximize QA+ - QA-.
2. Different parameters space in Q space and A space.
3. HRNN separate to two tricky things : use output layer or use hidden layer as decoder's softmax layer's input.
2016-05-22 :
1. Investigate different loss functions in chatting model.
2016-05-21 :
1. Hand out different research task to intern students.
2016-05-20 :
1. Testing denosing rnn generation model.
2016-05-19 :
1. Discover for denosing rnn.
2016-05-18 :
1. Modify model for crawler data.
2016-05-17 :
1. Code & Test HRNN model.
2016-05-16 :
1. Work done for CDSSM model.
2016-05-15 :
1. Test CDSSM model package version.
2016-05-13 :
1. Coding done CDSSM model package version. Wait to test.
2016-05-12 :
1. Begin to package CDSSM model for huilan.
2016-05-11 :
1. Prepare for paper sharing.
2. Finish CDSSM model in chatting process.
3. Start setup model & experiment in dialogue system.
2016-05-10 :
1. Finish test CDSSM model in chatting, find original data has some problem.
2. Read paper:
A Hierarchical Recurrent Encoder-Decoder for Generative Context-Aware Query Suggestion
A Neural Network Approach to Context-Sensitive Generation of Conversational Responses
Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models
Neural Responding Machine for Short-Text Conversation
2016-05-09 :
1. Test CDSSM model in chatting model.
2. Read paper :
Learning from Real Users Rating Dialogue Success with Neural Networks for Reinforcement Learning in Spoken Dialogue Systems
SimpleDS A Simple Deep Reinforcement Learning Dialogue System
3. Code RNN by myself in tensorflow.
2016-05-08 :
Fix some problem in dialogue system team, and continue read some papers in dialogue system.
2016-05-07 :
Read some papers in dialogue system.
2016-05-06 :
Try to fix RNN-DSSM model in tensorflow. Failure..
2016-05-05 :
Coding for RNN-DSSM in tensorflow. Face an error when running rnn-dssm model in cpu : memory keep increasing.
Tensorflow's version in huilan is 0.7.0 and install by pip, this cause using error in creating gpu graph,
one possible solution is build tensorflow from source code.
Aiting Liu
2016-07-28: learn lesson linear model
2016-07-25 ~ 2016-07-27: read paper Intrinsic Subspace Evaluation of Word Embedding Representations [pdf]
2016-07-22 ~ 2016-07-23: run and modify lyrics generation model
2016-07-19 ~ 2016-07-21:
preprocess the 200,000 lyrics
2016-07-18: get 200,000 songs from http://www.cnlyric.com/ ( singer list from a-z)
2016-07-08: preprocess the lyrics from baidu music
2016-07-07: get 27963 songs from http://www.cnlyric.com/ (singerlist from A/B/C)
2016-07-06: try to get lyrics from http://www.kuwo.cn/ http://www.kugou.com/ http://y.qq.com/#type=index http://music.163.com/
2016-07-05: write lyrics spider, and get 56306 songs from http://music.baidu.com/
2016-07-04: learn tensorflow
2016-07-01: submit APSIPA2016 paper
2016-06-30: perfection paper
2016-06-29: complete the ordered word embedding's paper
2016-06-26: modify the ordered word embedding's paper
2016-06-25: complete ordered word embedding experiment,get 54 figures
2016-06-23: read Bengio's paper https://arxiv.org/pdf/1605.06069v3.pdf
2016-06-22: read Bengio's paper http://arxiv.org/pdf/1507.04808v3.pdf
2016-06-13:
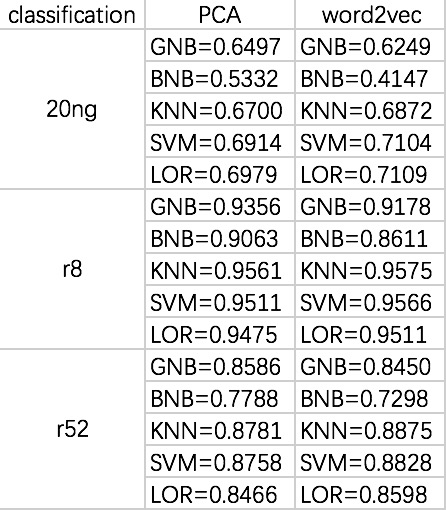

2016-06-12:
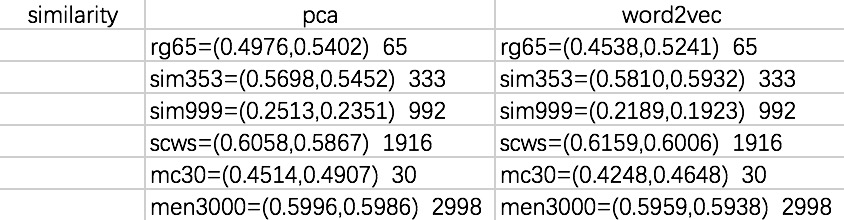

2016-06-05: complete the binary word embedding, find out that tensorflow does not provide logical derivation method.
2016-06-04: write the binary word embedding model
2016-06-01:
1.Record demo video of our Personalized Chatterbot
2.program the binary word embedding model
2016-05-31: debugging our Personalized Chatterbot
2016-05-30: complete our Personalized Chatterbot
2016-05-29:
1.scan Chao's code and modify it
2.run the modified program to get the eight hundred thousand sentences's whole matrix
2016-05-28:
1.complete the word2vec model in tensorflow
2.complete the first version of binary word embedding model
2016-05-25: .write my own version of word2vec model
2016-05-23:
1.get tensorflow's word2vec model from(https://github.com/tensorflow/tensorflow/tree/master/tensorflow/models/embedding) 2.learn word2vec_basic model 3.run word2vec.py and word2vec_optimized.py,we need a Chinese evaluation dataset if we want to use it directly
2016-05-22:
1.find the tf.logical_xor(x,y) method in tensorflow to compute Hamming distance.
2.learn tensorflow's word2vec model
2016-05-21:
1.read Lantian's paper 'Binary Speaker Embedding'
2.try to find a formula in tensorflow to compute Hamming distance.
2016-05-18:
Fetch American TV subtitles and process them into a specific format(12.6M)
(1.Sex and the City 2.Gossip Girl 3.Desperate Housewives 4.The IT Crowd 5.Empire 6.2 Broke Girls)
2016-05-16:Process the data collected from the interview site,interview books and American TV subtitles(38.2M+23.2M)
2016-05-11:
Fetch American TV subtitles
(1.Friends 2.Big Bang Theory 3.The descendant of the Sun 4.Modern Family 5.House M.D. 6.Grey's Anatomy)
2016-05-08:Fetch data from 'http://news.ifeng.com/' and 'http://www.xinhuanet.com/'(13.4M)
2016-05-07:Fetch data from 'http://fangtan.china.com.cn/' and interview books (10M)
2016-05-04:Establish the overall framework of our chat robot,and continue to build database
Ziwei Bai
2016-07-21~ 2016-07-22:
build RNN model for TTS
2016-07-18 ~ 2016-07-19:
1、run bottleneck model with different parameters
2、 prepare Bi-weekly report
3、draw a map to compare different model,
2016-07-14 ~ 2016-07-15:
build bottleneck model(non linear layer : sigmoid relu tanh)
2016-07-12 ~ 2016-07-13:
modify the TTS program
1、separate classify and transfer
2、separate lf0 and mgc
2016-07-11:
finish the patent
2016-07-07 ~ 2016-07-08:
1、program LSTM with tensorflow (still has some bug)
2、learn paper 'Fast,Compact,and High Quality LSTM-RNN Based Statistical Parametric Speech Synthesizers fot Mobile Devices'
2016-07-06:
finish the second edition of patent
2016-07-05:
finish the fisrt edition of patent
2016-07-04:
1、debug and run the chatting model with softmax
2、determine model for patent of ‘LSTM-based modern text to the poetry conversion technology’
2016-07-01:
the model updated yesterday can't converge,try to learn tf.sampled_softmax_loss()
2016-06-30:
convert our chatting model from Negative sample to softmax and convert the cost from cosine to cross-entropy
tf.softmax()
2016-06-29:
learn paper 'Neural Responding Machine for Short-Text Conversation'
2016-06-23:
learn paper ‘Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models’
http://arxiv.org/pdf/1507.04808v3.pdf
2016-06-22:
1、construct vector for word cut by jieba
2、retrain the cdssm model with new word vector(still run)
2016-06-04:
1、modify the interface for QA system
2、pull together the interface and QA system
2016-06-01:
1、add data source and Performance Test results in work report
2、learn pyQt
2016-05-30:
complete the work report
2016-05-29:
write code for inputting a question ,return a answer sets whose question is most similar to the input question
2016-05-25:
1、learn DSSM
2、 complete the first edition of work report
3、construct basic Q&A(name,age,job and so on)
2016-05-23:
write code for searching question in 'zhihu.sogou.com' and searching answer in zhihu
2016-05-21:
learn the second half of paper 'A Neural Conversational Model'
2016-05-18:
1、crawl QA pairs from http://www.chinalife.com.cn/publish/zhuzhan/index.html and http://www.pingan.com/ 2、find paper 'A Neural Conversational Model' from google scholar and learn the first half of it.
2016-05-16:
1、find datasets in paper 'Neural Responding Machine for Short-Text Conversation'
2、reconstruct 15 scripts into our expected formula
2016-05-15:
1、find 130 scripts
2、 reconstruct 11 scripts into our expected formula
problem:many files cann't distinguish between dialogue and scenario describes by program.
2016-05-11:
1、read paper“Movie-DiC: a Movie Dialogue Corpus for Research and Development”
2、reconstruct a new film scripts into our expected formula
2016-05-08: convert the pdf we found yesterday into txt,and reconstruct the data into our expected formula
2016-05-07: Finding 9 Drama scripts and 20 film scripts
2016-05-04:Finding and dealing with the data for QA system
Generation Model (Aodong li)
- 2016-05-21 : Complete my biweekly report and take over new tasks -- low-frequency words
- 2016-05-20 :
Optimize my code to speed up Train the models with GPU However, it does not converge :(
- 2016-05-19 : Code a simple version of keywords-to-sequence model and train the model
- 2016-05-18 : Debug keywords-to-sequence model and train the model
- 2016-05-17 : make technical details clear and code keywords-to-sequence model
- 2016-05-16 : Denoise and segment more lyrics and prepare for keywords to sequence model
- 2016-05-15 : Train some different models and analyze performance: song to song, paragraph to paragraph, etc.
- 2016-05-12 : complete sequence to sequence model's prediction process and the whole standard sequence to sequence lstm-based model v0.0
- 2016-05-11 : complete sequence to sequence model's training process in Theano
- 2016-05-10 : complete sequence to sequence lstm-based model in Theano
- 2016-05-09 : try to code sequence to sequence model
- 2016-05-08 :
denoise and train word vectors of Lijun Deng's lyrics (110+ pieces) decide on using raw sequence to sequence model
- 2016-05-07 :
study attention-based model learn some details about the poem generation model change my focus onto lyrics generation model
- 2016-05-06 : read the paper about poem generation and learn about LSTM
- 2016-05-05 : check in and have an overview of generation model
jiyuan zhang
- 2016-05-01~06 :modify input format and run lstmrbm model (16-beat,32-beat,bar)
- 2016-05-09~13:
Modify model parameters and run model ,the result is not ideal yet According to teacher Wang's opinion, in the generation stage,replace random generation with the maximum probability generation
- 2016-05-24~27 :check the blog's codes and understand the model and input format details on the blog